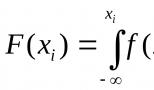Основы выборочного исследования и формирования простой случайной выборки. Генеральная совокупность и выборочное исследование. Статистическая достоверность Критерии выборки данных
Выборка или выборочная совокупность - множество случаев (испытуемых, объектов, событий, образцов), с помощью определённой процедуры выбранных изгенеральной совокупности для участия в исследовании.
Характеристики выборки:
§ Качественная характеристика выборки – кого именно мы выбираем и какие способы построения выборки мы для этого используем.
§ Количественная характеристика выборки – сколько случаев выбираем, другими словами объём выборки.
Необходимость выборки
§ Объект исследования очень обширный. Например, потребители продукции глобальной компании – огромное количество территориально разбросанных рынков.
§ Существует необходимость в сборе первичной информации.
Объём выборки
Объём выборки - число случаев, включённых в выборочную совокупность. Из статистических соображений рекомендуется, чтобы число случаев составляло не менее 30-35.
Зависимые и независимые выборки
При сравнении двух (и более) выборок важным параметром является их зависимость. Если можно установить гомоморфную пару (то есть, когда одному случаю из выборки X соответствует один и только один случай из выборки Y и наоборот) для каждого случая в двух выборках (и это основание взаимосвязи является важным для измеряемого на выборках признака), такие выборки называются зависимыми . Примеры зависимых выборок:
§ пары близнецов,
§ два измерения какого-либо признака до и после экспериментального воздействия,
§ мужья и жёны
В случае, если такая взаимосвязь между выборками отсутствует, то эти выборки считаются независимыми , например:
§ мужчины и женщины,
§ психологи и математики.
Соответственно, зависимые выборки всегда имеют одинаковый объём, а объём независимых может отличаться.
Сравнение выборок производится с помощью различных статистических критериев:
§ t-критерий Стьюдента
§ Критерий Уилкоксона
§ U-критерий Манна-Уитни
§ Критерий знаков
Репрезентативность
Выборка может рассматриваться в качестве репрезентативной или нерепрезентативной.
Пример нерепрезентативной выборки
В США одним из наиболее известных исторических примеров нерепрезентативной выборки считается случай, происшедший во время президентских выборов в 1936году . Журнал «Литрери Дайджест», успешно прогнозировавший события нескольких предшествующих выборов, ошибся в своих предсказаниях, разослав десять миллионов пробных бюллетеней своим подписчикам, а также людям, выбранным по телефонным книгам всей страны и людям из регистрационных списков автомобилей. В 25 % вернувшихся бюллетеней (почти 2,5 миллиона) голоса были распределены следующим образом:
§ 57 % отдавали предпочтение кандидату-республиканцу Альфу Лэндону
§ 40 % выбрали действующего в то время президента-демократа Франклина Рузвельта
На действительных же выборах, как известно, победил Рузвельт, набрав более 60 % голосов. Ошибка «Литрери Дайджест» заключалась в следующем: желая увеличить репрезентативность выборки, - так как им было известно, что большинство их подписчиков считают себя республиканцами, - они расширили выборку за счёт людей, выбранных из телефонных книг и регистрационных списков. Однако они не учли современных им реалий и в действительности набрали ещё больше республиканцев: во время Великой депрессии обладать телефонами и автомобилями могли себе позволить в основном представители среднего и высшего класса (то есть большинство республиканцев, а не демократов).
Виды плана построения групп из выборок
Выделяют несколько основных видов плана построения групп :
1. Исследование с экспериментальной и контрольной группами, которые ставятся в разные условия.
§ Исследование с экспериментальной и контрольной группами с привлечением стратегии попарного отбора
2. Исследование с использованием только одной группы - экспериментальной.
3. Исследование с использованием смешанного (факторного) плана - все группы ставятся в разные условия.
]Типы выборки
Выборки делятся на два типа:
§ вероятностные
§ невероятностные
Вероятностные выборки
1. Простая вероятностная выборка:
§ Простая повторная выборка. Использование такой выборки основывается на предположении, что каждый респондент с равной долей вероятности может попасть в выборку. На основе списка генеральной совокупности составляются карточки с номерами респондентов. Они помещаются в колоду, перемешиваются и из них наугад вынимается карточка, записывается номер, потом возвращается обратно. Далее процедура повторяется столько раз, какой объём выборки нам необходим. Минус: повторение единиц отбора.
Процедура построения простой случайной выборки включает в себя следующие шаги:
1. необходимо получить полный список членов генеральной совокупности и пронумеровать этот список. Такой список, напомним, называется основой выборки;
2. определить предполагаемый объем выборки, то есть ожидаемое число опрошенных;
3. извлечь из таблицы случайных чисел столько чисел, сколько нам требуется выборочных единиц. Если в выборке должно оказаться 100 человек, из таблицы берут 100 случайных чисел. Эти случайные числа могут генерироваться компьютерной программой.
4. выбрать из списка-основы те наблюдения, номера которых соответствуют выписанным случайным числам
§ Простая случайная выборка имеет очевидные преимущества. Этот метод крайне прост для понимания. Результаты исследования можно распространять на изучаемую совокупность. Большинство подходов к получению статистических выводов предусматривают сбор информации с помощью простой случайной выборки. Однако метод простой случайной выборки имеет как минимум четыре существенных ограничения:
1. зачастую сложно создать основу выборочногo наблюдения, которая позволила бы провести простую случайную выборку.
2. результатом применения простой случайной выборки может стать большая совокупность, либо совокупность, распределенная по большой географической территории, что значительно увеличивает время и стоимость сбора данных.
3. результаты применения простой случайной выборки часто характеризуются низкой точностью и большей стандартной ошибкой, чем результаты применения других вероятностных методов.
4. в результате применения SRS может сформироваться нерепрезентативная выборка. Хотя выборки, полученные простым случайным отбором, в среднем адекватно представляют генеральную совокупность, некоторые из них крайне некорректно представляют изучаемую совокупность. Вероятность этого особенно велика при небольшом объеме выборки.
§ Простая бесповторная выборка. Процедура построения выборки такая же, только карточки с номерами респондентов не возвращаются обратно в колоду.
1. Систематическая вероятностная выборка. Является упрощенным вариантом простой вероятностной выборки. На основе списка генеральной совокупности через определённый интервал (К) отбираются респонденты. Величина К определяется случайно. Наиболее достоверный результат достигается при однородной генеральной совокупности, иначе возможны совпадение величины шага и каких-то внутренних циклических закономерностей выборки (смешение выборки). Минусы: такие же как и в простой вероятностной выборке.
2. Серийная (гнездовая) выборка. Единицы отбора представляют собой статистические серии (семья, школа, бригада и т. п.). Отобранные элементы подвергаются сплошному обследованию. Отбор статистических единиц может быть организован по типу случайной или систематической выборки. Минус: Возможность большей однородности, чем в генеральной совокупности.
3. Районированная выборка. В случае неоднородной генеральной совокупности, прежде, чем использовать вероятностную выборку с любой техникой отбора, рекомендуется разделить генеральную совокупность на однородные части, такая выборка называется районированной. Группами районирования могут выступать как естественные образования (например, районы города), так и любой признак, заложенный в основу исследования. Признак, на основе которого осуществляется разделение, называется признаком расслоения и районирования.
4. «Удобная» выборка. Процедура «удобной» выборки состоит в установлении контактов с «удобными» единицами выборки - с группой студентов, спортивной командой, с друзьями и соседями. Если необходимо получить информацию о реакции людей на новую концепцию, такая выборка вполне обоснована. «Удобную» выборку часто используют для предварительного тестирования анкет.
Невероятностные выборки
Отбор в такой выборке осуществляется не по принципам случайности, а по субъективным критериям – доступности, типичности, равного представительства и т.д.
1. Квотная выборка – выборка строится как модель, которая воспроизводит структуру генеральной совокупности в виде квот (пропорций) изучаемых признаков. Число элементов выборки с различным сочетанием изучаемых признаков определяется с таким расчётом, чтобы оно соответствовало их доле (пропорции) в генеральной совокупности. Так, например, если генеральная совокупность у нас представлена 5000 человек, из них 2000 женщин и 3000 мужчин, тогда в квотной выборке у нас будут 20 женщин и 30 мужчин, либо 200 женщин и 300 мужчин. Квотированные выборки чаще всего основываются на демографических критериях: пол, возраст, регион, доход, образование и прочих. Минусы: обычно такие выборки нерепрезентативны, т.к. нельзя учесть сразу несколько социальных параметров. Плюсы: легкодоступный материал.
2. Метод снежного кома. Выборка строится следующим образом. У каждого респондента, начиная с первого, просятся контакты его друзей, коллег, знакомых, которые подходили бы под условия отбора и могли бы принять участие в исследовании. Таким образом, за исключением первого шага, выборка формируется с участием самих объектов исследования. Метод часто применяется, когда необходимо найти и опросить труднодоступные группы респондентов (например, респондентов, имеющих высокий доход, респондентов, принадлежащих к одной профессиональной группе, респондентов, имеющих какие-либо схожие хобби/увлечения и т.д.)
3. Стихийная выборка – выборка так называемого «первого встречного». Часто используется в теле- и радиоопросах. Размер и состав стихийных выборок заранее не известен, и определяется только одним параметром – активностью респондентов. Минусы: невозможно установить какую генеральную совокупность представляют опрошенные, и как следствие – невозможность определить репрезентативность.
4. Маршрутный опрос – часто используется, если единицей изучения является семья. На карте населённого пункта, в котором будет производиться опрос, нумеруются все улицы. С помощью таблицы (генератора) случайных чисел отбираются большие числа. Каждое большое число рассматривается как состоящее из 3-х компонентов: номер улицы (2-3 первых числа), номер дома, номер квартиры. Например, число 14832: 14 – это номер улицы на карте, 8 – номер дома, 32 – номер квартиры.
5. Районированная выборка с отбором типичных объектов. Если после районирования из каждой группы отбирается типичный объект, т.е. объект, который по большинству изучаемых в исследовании характеристик приближается к средним показателям, такая выборка называется районированной с отбором типичных объектов.
6.Модальная выборка. 7.экспертная выборка. 8.Гетерогенная выборка.
Стратегии построения групп
Отбор групп для их участия в психологическом эксперименте осуществляется с помощью различных стратегий, которые нужны для того, чтобы обеспечить максимально возможное соблюдение внутренней и внешней валидности .
§ Рандомизация (случайный отбор)
§ Попарный отбор
§ Стратометрический отбор
§ Приближённое моделирование
§ Привлечение реальных групп
Рандомизация
Рандомизация , или случайный отбор , используется для создания простых случайных выборок. Использование такой выборки основывается на предположении, что каждый член популяции с равной вероятностью может попасть в выборку. Например, чтобы сделать случайную выборку из 100 студентов вуза, можно сложить бумажки с именами всех студентов вуза в шляпу, а затем достать из неё 100 бумажек - это будет случайным отбором (Гудвин Дж., с. 147).
Попарный отбор
Попарный отбор - стратегия построения групп выборки, при котором группы испытуемых составляются из субъектов, эквивалентных по значимым для эксперимента побочным параметрам. Данная стратегия эффективна для экспериментов с использованием экспериментальных и контрольных групп с лучшим вариантом - привлечением близнецовых пар (моно- и дизиготных), так как позволяет создать...
Стратометрический отбор
Стратометрический отбор - рандомизация с выделением страт (или кластеров). При данном способе формирования выборки генеральная совокупность делится на группы (страты), обладающие определёнными характеристиками (пол, возраст, политические предпочтения, образование, уровень доходов и др.), и отбираются испытуемые с соответствующими характеристиками.
Приближённое моделирование
Приближённое моделирование - составление ограниченных выборок и обобщение выводов об этой выборке на более широкую популяцию. Например, при участии в исследовании студентов 2-го курса университета, данные этого исследования распространяются на «людей в возрасте от 17 до 21 года». Допустимость подобных обобщений крайне ограничена.
Приближенное моделирование – формирование модели, которая для четко оговоренного класса систем (процессов) описывает его поведение (или нужные явления) с приемлемой точностью.
Выборка в 1С 8.2 и 8.3- специализированный способ перебора записей таблиц информационной базы. Рассмотрим подробно, что такое выборка и как её использовать.
Что такое выборка в 1С?
Выборка — способ перебора информации в 1С, который заключается в последовательной установки курсора на последующей записи. Выборку в 1С можно получить из результата запроса и из менеджера объектов, например, документов или справочников.
Пример получения и перебора из менеджера объекта:
Выборка = Справочники. Банки. Выбрать() ; Пока Выборка. Следующий() Цикл КонецЦикла ;
Пример получения выборки из запроса:
Получите 267 видеоуроков по 1С бесплатно:
Запрос = Новый Запрос("Выбрать Ссылка, Код, Наименование Из Справочник.Банки" ) ; Выборка = Запрос. Выполнить() . Выбрать() ; Пока Выборка. Следующий() Цикл //производим интересующие действия со справочником "Банки" КонецЦикла ;Оба перечисленных выше примера получают одинаковые наборы данных для перебора.
Методы Выборки 1С 8.3
Выборка имеет большое количество методов, рассмотрим их подробней:
- Выбрать() — метод, с помощью которого получают непосредственно выборку. Из выборки можно получить еще одну, подчиненную, выборку если указан тип обхода «по группировкам».
- Владелец() — метод, обратный Выбрать(). Позволяет получить «родительскую» выборка запроса.
- Следующий() — метод, производящий перевод курсора на следующую запись. Если запись существует, возвращает Истина, если записи закончились — Ложь.
- НайтиСледующий() — очень полезный метод, с помощью которого можно выполнять перебор только нужных поле по значению отбора (отбор — структура полей).
- СледующийПоЗначениюПоля() — позволяет получить следующую запись с отличным от текущего положения значения. Например, необходимо перебрать все записи с уникальный значением поля «Контрагент»: Выборка.СледующийПоЗначениюПоля(«Контрагент»).
- Сбросить() — позволяет сбросить текущее расположение курсора и установить его в первоначальное положение.
- Количество() — возвращает количество записей в выборке.
- Получить() — с помощью метода можно можно установить курсор на нужной записи по значению индекса.
- Уровень() — уровень в иерархии текущей записи (число).
- ТипЗаписи() — отображает тип записи — ДетальнаяЗапись, ИтогПоГруппировке, ИтогПоИерархии или ОбщийИтог
- Группировка() — возвращает имя текущей группировки, если запись не является группировкой — пустую строку.
Если Вы начинаете изучать 1С программирование, рекомендуем наш бесплатный курс (не забудьте
Статистическая совокупность — множество единиц, обладающих массовостью, типичностью, качественной однородностью и наличием вариации.
Статистическая совокупность состоит из материально существующих объектов (Работники, предприятия, страны, регионы), является объектом .
Единица совокупности — каждая конкретная единица статистической совокупности.
Одна и та же статистическая совокупность может быть однородна по одному признаку и неоднородна по другому.
Качественная однородность — сходство всех единиц совокупности по какому-либо признаку и несходство по всем остальным.
В статистической совокупности отличия одной единицы совокупности от другой чаще имеют количественную природу. Количественные изменения значений признака разных единиц совокупности называются вариацией.
Вариация признака — количественное изменение признака (для количественного признака) при переходе от одной единицы совокупности к другой.
Признак — это свойство, характерная черта или иная особенность единиц, объектов и явлений, которая может быть наблюдаема или измерена. Признаки делятся на количественные и качественные. Многообразие и изменчивость величины признака у отдельных единиц совокупности называется вариацией .
Атрибутивные (качественные) признаки не поддаются числовому выражению (состав населения по полу). Количественные признаки имеют числовое выражение (состав населения по возрасту).
Показатель — это обобщающая количественно качественная характеристика какого-либо свойства единиц или совокупности в целом в конкретных условиях времени и места.
Система показателей — это совокупность показателей всесторонне отражающих изучаемое явление.
Например, изучается зарплата:- Признак — оплата труда
- Статистическая совокупность — все работники
- Единица совокупности — каждый работник
- Качественная однородность — начисленная зарплата
- Вариация признака — ряд цифр
Генеральная совокупность и выборка из нее
Основу составляет множество данных, полученных в результате измерения одного или нескольких признаков. Реально наблюдаемая совокупность объектов, статистически представленная рядом наблюдений случайной величины , является выборкой , а гипотетически существующая (домысливаемая) — генеральной совокупностью . Генеральная совокупность может быть конечной (число наблюдений N = const ) или бесконечной (N = ∞ ), а выборка из генеральной совокупности — это всегда результат ограниченного ряда наблюдений. Число наблюдений , образующих выборку, называется объемом выборки . Если объем выборки достаточно велик (n → ∞ ) выборка считается большой , в противном случае она называется выборкой ограниченного объема . Выборка считается малой , если при измерении одномерной случайной величины объем выборки не превышает 30 (n <= 30 ), а при измерении одновременно нескольких (k ) признаков в многомерном пространстве отношение n к k не превышает 10 (n/k < 10) . Выборка образует вариационный ряд , если ее члены являются порядковыми статистиками , т. е. выборочные значения случайной величины Х упорядочены по возрастанию (ранжированы), значения же признака называются вариантами .
Пример . Практически одна и та же случайно отобранная совокупность объектов — коммерческих банков одного административного округа Москвы, может рассматриваться как выборка из генеральной совокупности всех коммерческих банков этого округа, и как выборка из генеральной совокупности всех коммерческих банков Москвы, а также как выборка из коммерческих банков страны и т.д.
Основные способы организации выборки
Достоверность статистических выводов и содержательная интерпретация результатов зависит от репрезентативности выборки, т.е. полноты и адекватности представления свойств генеральной совокупности, по отношению к которой эту выборку можно считать представительной. Изучение статистических свойств совокупности можно организовать двумя способами: с помощью сплошного и несплошного . Сплошное наблюдение предусматривает обследование всех единиц изучаемой совокупности , а несплошное (выборочное) наблюдение — только его части.
Существуют пять основных способов организации выборочного наблюдения:
1. простой случайный отбор , при котором объектов случайно извлекаются из генеральной совокупности объектов (например с помощью таблицы или датчика случайных чисел), причем каждая из возможных выборок имеют равную вероятность. Такие выборки называются собственно-случайными ;
2. простой отбор с помощью регулярной процедуры осуществляется с помощью механической составляющей (например, даты, дня недели, номера квартиры, буквы алфавита и др.) и полученные таким способом выборки называются механическими ;
3. стратифицированный отбор заключается в том, что генеральная совокупность объема подразделяется на подсовокупности или слои (страты) объема так что . Страты представляют собой однородные объекты с точки зрения статистических характеристик (например, население делится на страты по возрастным группам или социальной принадлежности; предприятия — по отраслям). В этом случае выборки называются стратифицированными (иначе, расслоенными, типическими, районированными );
4. методы серийного отбора используются для формирования серийных или гнездовых выборок . Они удобны в том случае, если необходимо обследовать сразу "блок" или серию объектов (например, партию товара, продукцию определенной серии или население при территориально-административном делении страны). Отбор серий можно осуществить собственно-случайным или механическим способом. При этом проводится сплошное обследование определенной партии товара, или целой территориальной единицы (жилого дома или квартала);
5. комбинированный (ступенчатый) отбор может сочетать в себе сразу несколько способов отбора (например, стратифицированный и случайный или случайный и механический); такая выборка называется комбинированной .
Виды отбора
По виду различаются индивидуальный, групповой и комбинированный отбор. При индивидуальном отборе в выборочную совокупность отбираются отдельные единицы генеральной совокупности, при групповом отборе — качественно однородные группы (серии) единиц, а комбинированный отбор предполагает сочетание первого и второго видов.
По методу отбора различают повторную и бесповторную выборку.
Бесповторным называется отбор, при котором попавшая в выборку единица не возвращается в исходную совокупность и в дальнейшем выборе не участвует; при этом численность единиц генеральной совокупности N сокращается в процессе отбора. При повторном отборе попавшая в выборку единица после регистрации возвращается в генеральную совокупность и таким образом сохраняет равную возможность наряду с другими единицами быть использованной в дальнейшей процедуре отбора; при этом численность единиц генеральной совокупности N остается неизменной (метод в социально-экономических исследованиях применяется редко). Однако, при большом N (N → ∞) формулы для бесповторного отбора приближаются к аналогичным для повторного отбора и практически чаще используются последние (N = const ).
Основные характеристики параметров генеральной и выборочной совокупности
В основе статистических выводов проведенного исследования лежит распределение случайной величины , наблюдаемые же значения (х 1 , х 2 , … , х n) называются реализациями случайной величины Х (n — объем выборки). Распределение случайной величины в генеральной совокупности носит теоретический, идеальный характер, а ее выборочный аналог является эмпирическим распределением. Некоторые теоретические распределения заданы аналитически, т.е. их параметры определяют значение функции распределения в каждой точке пространства возможных значений случайной величины . Для выборки же функцию распределения определить трудно, а иногда невозможно, поэтому параметры оценивают по эмпирическим данным, а затем их подставляют в аналитическое выражение, описывающее теоретическое распределение. При этом предположение (или гипотеза ) о виде распределения может быть как статистически верным, так и ошибочным. Но в любом случае восстановленное по выборке эмпирическое распределение лишь грубо характеризует истинное. Важнейшими параметрами распределений являются математическое ожидание и дисперсия .
По своей природе распределения бывают непрерывными и дискретными . Наиболее известным непрерывным распределением является нормальное . Выборочными аналогами параметров идля него являются: среднее значение и эмпирическая дисперсия . Среди дискретных в социально-экономических исследованиях наиболее часто применяется альтернативное (дихотомическое) распределение. Параметр математического ожидания этого распределения выражает относительную величину (или долю ) единиц совокупности, которые обладают изучаемым признаком (она обозначена буквой ); доля совокупности, не обладающая этим признаком, обозначается буквой q (q = 1 — p) . Дисперсия же альтернативного распределения также имеет эмпирический аналог .
В зависимости от вида распределения и от способа отбора единиц совокупности по-разному вычисляются характеристики параметров распределения. Основные из них для теоретического и эмпирического распределений приведены в табл. 1.
Долей выборки k n называется отношение числа единиц выборочной совокупности к числу единиц генеральной совокупности:
k n = n/N .
Выборочная доля w — это отношение единиц, обладающих изучаемым признаком x к объему выборки n :
w = n n /n .
Пример. В партии товара, содержащей 1000 ед., при 5% выборке доля выборки k n в абсолютной величине составляет 50 ед. (n = N*0,05); если же в этой выборке обнаружено 2 бракованных изделия, то выборочная доля брака w составит 0,04 (w = 2/50 = 0,04 или 4%).
Так как выборочная совокупность отлична от генеральной, то возникают ошибки выборки .
Таблица 1. Основные параметры генеральной и выборочной совокупностей
Ошибки выборки
При любом (сплошном и выборочном) могут встретиться ошибки двух видов: регистрации и репрезентативности. Ошибки регистрации могут иметь случайный и систематический характер. Случайные ошибки складываются из множества различных неконтролируемых причин, носят непреднамеренный характер и обычно по совокупности уравновешивают друг друга (например, изменения показателей прибора при температурных колебаниях в помещении).
Систематические ошибки тенденциозны, так как нарушают правила отбора объектов в выборку (например, отклонения в измерениях при изменении настройки измерительного прибора).
Пример. Для оценки социального положения населения в городе предусмотрено обследовать 25% семей. Если при этом выбор каждой четвертой квартиры основан на ее номере, то существует опасность отобрать все квартиры только одного типа (например, однокомнатные), что обеспечит систематическую ошибку и исказит результаты; выбор же номера квартиры по жребию более предпочтителен, так как ошибка будет случайной.
Ошибки репрезентативности присущи только выборочному наблюдению, их невозможно избежать и они возникают в результате того, что выборочная совокупность не полностью воспроизводит генеральную. Значения показателей, получаемых по выборке, отличаются от показателей этих же величин в генеральной совокупности (или получаемых при сплошном наблюдении).
Ошибка выборочного наблюдения есть разность между значением параметра в генеральной совокупности и ее выборочным значением. Для среднего значения количественного признака она равна: , а для доли (альтернативного признака) — .
Ошибки выборки свойственны только выборочным наблюдениям. Чем больше эти ошибки, тем больше эмпирическое распределение отличается от теоретического. Параметры эмпирического распределения и являются случайными величинами, следовательно, ошибки выборки также являются случайными величинами, могут принимать для разных выборок разные значения и поэтому принято вычислять среднюю ошибку .
Средняя ошибка выборки есть величина , выражающая среднее квадратическое отклонение выборочной средней от математического ожидания. Эта величина при соблюдении принципа случайного отбора зависит прежде всего от объема выборки и от степени варьирования признака: чем больше и чем меньше вариация признака (следовательно, и значение ), тем меньше величина средней ошибки выборки . Соотношение между дисперсиями генеральной и выборочной совокупностей выражается формулой:
т.е. при достаточно больших можно считать, что . Средняя ошибка выборки показывает возможные отклонения параметра выборочной совокупности от параметра генеральной. В табл. 2 приведены выражения для вычисления средней ошибки выборки при разных методах организации наблюдения.
Таблица 2. Средняя ошибка (m) выборочных средней и доли для разных видов выборки
Где - средняя из внутригрупповых выборочных дисперсий для непрерывного признака;
Средняя из внутригрупповых дисперсий доли;
— число отобранных серий, — общее число серий;
 ,
,
где — средняя -й серии;
— общая средняя по всей выборочной совокупности для непрерывного признака;
 ,
,
где — доля признака в -й серии;
— общая доля признака по всей выборочной совокупности.
Однако о величине средней ошибки можно судить лишь с определенной, вероятностью Р (Р ≤ 1). Ляпунов А.М. доказал, что распределение выборочных средних , a следовательно, и их отклонений от генеральной средней, при достаточно большом числе приближенно подчиняется нормальному закону распределения при условии, что генеральная совокупность обладает конечной средней и ограниченной дисперсией.
Математически это утверждение для средней выражается в виде:

а для доли выражение (1) примет вид:
где  -
есть предельная ошибка выборки
, которая кратна величине средней ошибки выборки ,
а коэффициент кратности — есть критерий Стьюдента ("коэффициент доверия"), предложенный У.С. Госсетом (псевдоним "Student"); значения для разного объема выборки хранятся в специальной таблице.
-
есть предельная ошибка выборки
, которая кратна величине средней ошибки выборки ,
а коэффициент кратности — есть критерий Стьюдента ("коэффициент доверия"), предложенный У.С. Госсетом (псевдоним "Student"); значения для разного объема выборки хранятся в специальной таблице.

Следовательно, выражение (3) может быть прочитано так: с вероятностью Р = 0,683 (68,3%) можно утверждать, что разность между выборочной и генеральной средней не превысит одной величины средней ошибки m (t = 1) , с вероятностью Р = 0,954 (95,4%) — что она не превысит величины двух средних ошибок m (t = 2) , с вероятностью Р = 0,997 (99,7%) — не превысит трех значений m (t = 3) . Таким образом, вероятность того, что эта разность превысит трехкратную величину средней ошибки определяет уровень ошибки и составляет не более 0,3% .
В табл. 3 приведены формулы для вычисления предельной ошибки выборки.
Таблица 3. Предельная ошибка (D) выборки для средней и доли (р) для разных видов выборочного наблюдения
Распространение выборочных результатов на генеральную совокупность
Конечной целью выборочного наблюдения является характеристика генеральной совокупности. При малых объемах выборки эмпирические оценки параметров ( и ) могут существенно отклоняться от их истинных значений ( и ). Поэтому возникает необходимость установить границы, в пределах которых для выборочных значений параметров ( и ) лежат истинные значения ( и ).
Доверительным интервалом какого-либо параметра θгенеральной совокупности называется случайная область значений этого параметра, которая с вероятностью близкой к 1 (надежностью ) содержит истинное значение этого параметра.
Предельная ошибка выборки Δ позволяет определить предельные значения характеристик генеральной совокупности и их доверительные интервалы , которые равны:
Нижняя граница доверительного интервала получена путем вычитания предельной ошибки из выборочного среднего (доли), а верхняя — путем ее добавления.
Доверительный интервал для средней использует предельную ошибку выборки и для заданного уровня достоверности определяется по формуле:
Это означает, что с заданной вероятностью Р
, которая называется доверительным уровнем и однозначно определяется значением t
, можно утверждать, что истинное значение средней лежит в пределах от ![]() ,а истинное значение доли — в пределах от
,а истинное значение доли — в пределах от
При расчете доверительного интервала для трех стандартных доверительных уровней Р = 95%, Р = 99% и Р = 99,9% значение выбирается по . Приложения в зависимости от числа степеней свободы . Если объем выборки достаточно велик, то соответствующие этим вероятностям значения t равны: 1,96, 2,58 и 3,29 . Таким образом, предельная ошибка выборки позволяет определить предельные значения характеристик генеральной совокупности и их доверительные интервалы:
Распространение результатов выборочного наблюдения на генеральную совокупность в социально-экономических исследованиях имеет свои особенности, так как требует полноты представительности всех ее типов и групп. Основой для возможности такого распространения является расчет относительной ошибки :

где Δ % - относительная предельная ошибка выборки; , .
Существуют два основных метода распространения выборочного наблюдения на генеральную совокупность: прямой пересчет и способ коэффициентов .
Сущность прямого пересчета заключается в умножении выборочного среднего значения!!\overline{x} на объем генеральной совокупности .
Пример . Пусть среднее число детей ясельного возраста в городе оценено выборочным методом и составило человека. Если в городе 1000 молодых семей, то число необходимых мест в муниципальных детских яслях получают умножением этой средней на численность генеральной совокупности N = 1000, т.е. составит 1200 мест.
Способ коэффициентов целесообразно использовать в случае, когда выборочное наблюдение проводится с целью уточнения данных сплошного наблюдения.
При этом используют формулу:
где все переменные — это численность совокупности:
Необходимый объем выборки
Таблица 4. Необходимый объем (n) выборки для разных видов организации выборочного наблюдения
При планировании выборочного наблюдения с заранее заданным значением допустимой ошибки выборки необходимо правильно оценить требуемый объем выборки . Этот объем может быть определен на основе допустимой ошибки при выборочном наблюдении исходя из заданной вероятности , гарантирующей допустимую величину уровня ошибки (с учетом способа организации наблюдения). Формулы для определения необходимой численности выборки n легко получить непосредственно из формул предельной ошибки выборки. Так, из выражения для предельной ошибки:
непосредственно определяется объем выборки n :
Эта формула показывает, что с уменьшением предельной ошибки выборки Δ существенно увеличивается требуемый объем выборки , который пропорционален дисперсии и квадрату критерия Стьюдента .
Для конкретного способа организации наблюдения требуемый объем выборки вычисляется согласно формулам, приведенным в табл. 9.4.
Практические примеры расчета
Пример 1. Вычисление среднего значения и доверительного интервала для непрерывного количественного признака.
Для оценки скорости расчета с кредиторами в банке проведена случайная выборка 10 платежных документов. Их значения оказались равными (в днях): 10; 3; 15; 15; 22; 7; 8; 1; 19; 20.
Необходимо с вероятностью Р = 0,954 определить предельную ошибку Δ выборочной средней и доверительные пределы среднего времени расчетов.
Решение. Среднее значение вычисляется по формуле из табл. 9.1 для выборочной совокупности
![]()
Дисперсия вычисляется по формуле из табл. 9.1.
![]()
Средняя квадратическая погрешность дня.
Ошибка средней вычисляется по формуле:
![]()
т.е. среднее значение равно x ± m = 12,0 ± 2,3 дней .
Достоверность среднего составила
![]()
Предельную ошибку вычислим по формуле из табл. 9.3 для повторного отбора, так как численность генеральной совокупности неизвестна, и для Р = 0,954 уровня достоверности.
Таким образом, среднее значение равно `x ± D = `x ± 2m = 12,0 ± 4,6, т.е. его истинное значение лежит в пределах от 7,4 до16,6 дней.
Использование таблицы Стьюдента. Приложения позволяет заключить, что для n = 10 — 1 = 9 степеней свободы полученное значение достоверно с уровнем значимости a £ 0,001, т.е. полученное значение среднего достоверно отличается от 0.
Пример 2. Оценка вероятности (генеральной доли) р.
При механическом выборочном способе обследования социального положения 1000 семей выявлено, что доля малообеспеченных семей составила w = 0,3 (30%) (выборка была 2% , т.е. n/N = 0,02 ). Необходимо с уровнем достоверности р = 0,997 определить показатель р малообеспеченных семей во всем регионе.
Решение. По представленным значениям функции Ф(t) найдем для заданного уровня достоверности Р = 0,997 значение t = 3 (см. формулу 3). Предельную ошибку доли w определим по формуле из табл. 9.3 для бесповторного отбора (механическая выборка всегда является бесповторной):
Предельная относительная ошибка выборки в % составит:
Вероятность (генеральная доля) малообеспеченных семей в регионе составит р=w±Δ w , а доверительные пределы р вычисляются исходя из двойного неравенства:
w — Δ w ≤ p ≤ w — Δ w , т.е. истинное значение р лежит в пределах:
0,3 — 0,014 < p <0,3 + 0,014, а именно от 28,6% до 31,4%.
Таким образом, с вероятностью 0,997 можно утверждать, что доля малообеспеченных семей среди всех семей региона составляет от 28,6% до 31,4%.
Пример 3. Вычисление среднего значения и доверительного интервала для дискретного признака, заданного интервальным рядом.
В табл. 5. задано распределение заявок на изготовление заказов по срокам их выполнения предприятием.
Таблица 5. Распределение наблюдений по срокам появленияРешение. Средний срок выполнения заявок вычисляется по формуле:
Средний срок составит:
= (3*20 + 9*80 + 24*60 + 48*20 + 72*20)/200 = 23,1 мес.
Тот же ответ получим, если используем данные о р i из предпоследней колонки табл. 9.5, используя формулу:
Заметим, что середина интервала для последней градации находится путем искусственного ее дополнения шириной интервала предыдущей градации равной 60 — 36 = 24 мес.
Дисперсия вычисляется по формуле
![]()
где х i - середина интервального ряда.
Следовательно!!\sigma = \frac {20^2 + 14^2 + 1 + 25^2 + 49^2}{4}, а средняя квадратическая погрешность .
Ошибка средней вычисляется по формуле мес., т.е. среднее значение равно!!\overline{x} ± m = 23,1 ± 13,4.
Предельную ошибку вычислим по формуле из табл. 9.3 для повторного отбора, так как численность генеральной совокупности неизвестна, для 0,954 уровня достоверности:
Таким образом, среднее значение равно:
т.е. его истинное значение лежит в пределах от 0 до 50 мес.
Пример 4. Для определения скорости расчетов с кредиторами N = 500 предприятий корпорации в коммерческом банке необходимо провести выборочное исследование методом случайного бесповторного отбора. Определить необходимый объем выборки n, чтобы с вероятностью Р = 0,954 ошибка среднего значения выборки не превышала 3-х дней, если пробные оценки показали, что среднее квадратическое отклонение s составило 10 дней.
Решение . Для определения числа необходимых исследований n воспользуемся формулой для бесповторного отбора из табл. 9.4:

В ней значение t определяется из для уровня достоверности Р = 0,954. Оно равно 2. Среднее квадратическое значение s = 10, объем генеральной совокупности N = 500, а предельная ошибка среднего значения Δ x = 3. Подставляя эти значения в формулу, получим:
![]()
т.е. выборку достаточно составить из 41 предприятия, чтобы оценить требуемый параметр — скорость расчетов с кредиторами.
Понятие «репрезентативность» применительно к социологическим опросам - опросам общественного мнения - обладает почти магическим действием на людей. Сам термин «репрезентация» имеет кроме научного еще и явно политическое значение.
В чем причина? Все дело в том, что предполагается, что выборка (группа людей, отобранная для опроса) может репрезентировать (представлять) всю генеральную совокупность. Генеральной совокупностью в случае общероссийских опросов является все население страны. Теперь представим, что речь идет о политическом решении - поддержке законопроекта или голосовании на выборах. С помощью выборочного опроса мы получаем отличный механизм политической репрезентации - механизм, при котором небольшая группа людей может представлять мнение или позицию всего населения страны. Поэтому репрезентативности исследования отводится такое важное место.
Понятие репрезентативности используется, разумеется, не только в политических исследованиях. Термин применяется практически всегда, когда речь идет о больших исследованиях, будь то в сфере маркетинга, экономического поведения или образования.
Методология репрезентативных опросов
Как, опросив 1500 человек, можно делать выводы обо всех россиянах, которых более 140 миллионов (и даже избирателей более 110 миллионов)? Технология, которая стоит за репрезентативными опросами, основана на статистических законах. Ближайшим основанием служит закон больших чисел, или теорема Бернулли.
Упрощенно его смысл можно передать так. Предположим, у нас имеется некоторый признак, например количество осадков за день в Екатеринбурге в течение ХХ века. Если мы выпишем все его значения вместе с их частотой (это называется распределением), а затем случайно возьмем достаточно большое число случаев (то есть не все дни в ХХ веке, но достаточно много), то мы увидим, что распределение в нашей выборке будет очень похожим на распределение за весь ХХ век. Таким образом, если мы отбираем из совокупности некоторые единицы, они действительно могут представлять всю совокупность, и на самом деле нет необходимости собирать данные по всем случаям.
Однако имеется ключевое условие: это верно, только если производить отбор строго случайным образом. Единственной проблемой здесь может быть отклонение от случайности. Так, если мы возьмем только данные по осадкам за последние годы (например, потому что эти данные проще найти) или опросим 1500 своих знакомых (потому что с ними проще связаться), а не случайных людей, то выборка, конечно, не будет репрезентативной.
Представьте, что из 143,5 миллионов россиян вы случайным образом отбираете необходимые вам 1500 человек. Тогда, например, доля менеджеров среднего звена среди них будет приблизительно равна доле менеджеров среднего звена в генеральной совокупности, что и показывает, что ваша выборка может представлять всю совокупность. Может ли так получиться, что эти два показателя будут сильно различаться? Например, среди россиян он составляет 14%, а в выборке он составит только 1%? Теоретически это возможно, однако вероятность этого настолько мала, что ею можно пренебречь (примерно как встретить дракона на улице).
Более того, самое приятное в этой вероятности даже не то, что она мала, а то, что для случайных процессов эту вероятность можно вычислить. Мы можем сказать, с какой вероятностью наше выборочное значение отклонится от значения в генеральной совокупности на 13% (как в примере выше), а с какой, скажем, на 2,5%. Обычно, впрочем, делают наоборот: сначала определяют вероятность, с которой мы хотим, чтобы наше значение не отклонялось от значения в генеральной совокупности (чаще всего его фиксируют на уровне 95%), а потом уже смотрят, какова величина отклонения при том или ином размере выборки. Это отклонение называется доверительным интервалом, иногда его называют ошибкой выборки или статистической погрешностью - его часто приводят рядом с результатами опроса.
Итак, вероятность отклонения, величина отклонения (доверительный интервал) и размер выборки связаны между собой. Исходя из этого, формула для расчета размера выборки выглядит следующим образом:
где n - размер выборки, Δ - доверительный интервал, z - значение функции нормального распределения для данной вероятности отклонения (для вероятности 5% это значение составляет 1,96).
Это упрощенная формула, в реальных опросах используются несколько более сложные формулы. Эта формула также может давать сбой, если значение показателя сильно отличается от 50% (поэтому, например, эта формула не подойдет для того, чтобы оценить долю больных редким заболеванием в стране).
Вот что будет, если подставить в эту формулу некоторые значения:
Иными словами, если мы взяли случайную выборку россиян размером в 1600 человек и оценили какой-то показатель, например готовность голосовать за определенного политика, то с вероятностью 95% наша оценка не будет отличаться от готовности проголосовать за него среди всех россиян более чем на 2,45%.
Размер выборки
Итак, чем больше размер выборки, тем больше вероятность того, что мы будем ближе к доле в генеральной совокупности. Казалось бы, это значит, что нам нужно стараться приблизить выборку к 143,5 млн. На самом деле, как можно видеть из таблицы, природа случайных процессов такова, что с определенного момента вероятность попасть в интервал начинает повышаться очень медленно (и этот момент наступает довольно быстро). После того как мы отбираем 1500 единиц, как бы мы сильно ни увеличивали объем выборки, вероятность, что наше значение по выборке попадет в значение по генеральной совокупности, будет возрастать очень и очень медленно.
Фактически разницы между 1500 и 10 000 опрошенных почти нет. Где-то к 1500 мы уже можем говорить о том, что наши оценки будут отличаться от доли в генеральной совокупности на 2–3%. Если мы увеличиваем выборку дальше, то эта возможная ошибка будет уменьшаться, но очень незначительно. Иными словами, выборка в 100 000 лучше, чем выборка в 2500, но разница настолько мала, что не имеет смысла, а в случае социальных обследований и экономически не обоснована. Обычно увеличение выборки стоит дорого, и поэтому ее не имеет смысла раздувать ради того, чтобы выиграть один процентный пункт в величине доверительного интервала.
Важно, что в формуле вообще не фигурирует размер генеральной совокупности. Дело в том, что, когда генеральная совокупность велика (более 20 000), он практически не влияет на размер выборки. Таким образом, нам не нужно знать, сколько людей живет в России, чтобы построить репрезентативную выборку. Понятно, что выбирать 1500 из 2000, скорее всего, не имеет смысла - проще обследовать 2000 и получить точную оценку. Но, делая в случае необходимости выборку, мы получаем возможность обобщать ее результаты для генеральной совокупности. И по этой же причине размер выборки не будет отличаться для больших и маленьких стран.
Репрезентативность и точность
Чтобы понять смысл понятия «репрезентативность», давайте рассмотрим выборку в 15 человек. Как ни странно, если вы сделали ее случайно, она тоже репрезентативна. Более того, вы можете сделать выборку в одну единицу. Представьте ящик с шарами, откуда вы случайным образом берете один шар. Если это случайно выбранный шар, то он тоже будет репрезентировать все шары, что есть в этом ящике. Просто он будет репрезентировать их неточно . Почему? Потому что есть очень большая вероятность ошибиться. В следующий раз мы можем вытащить другой шар и получить другое представление о шарах в ящике. Репрезентировать неточно означает иметь большой разброс оценок.
Точно так же и 15 человек репрезентируют любую генеральную совокупность, но они репрезентируют ее неточно, потому что погрешность, доверительный интервал очень велики. Нам придется добавлять по +/- 33%, чтобы получить 95% вероятности того, что мы попадем в интервал. Если мы готовы это допустить, то берем 15 человек, выясняем, что 7 из них - это менеджеры среднего звена, а далее получаем оценку, что 7/15 от совокупности, то есть 47% +/- 33%, - это и есть оценка доли менеджеров в генеральной совокупности, и это абсолютно корректный вывод. Просто он не имеет никакой ценности. Это мы могли сказать и без обследования. Поэтому, планируя выборку, имеет смысл достигать такого объема, который будет целесообразным с точки зрения соотношения затрат и эффективности.
Все сказанное призвано донести одну простую мысль, которую очень часто не осознают: объем выборки не связан с ее репрезентативностью .
Маленькая выборка неточна, но она все равно может быть репрезентативной. Объемы выборок, которые используются сегодня в массовых опросах в России, почти всегда обладают достаточно высокой точностью.
Угрожает же репрезентативности выборки не ее объем, а смещение, то есть отклонение от принципа случайности.
Нарушение принципа случайности
Если мы начинаем выбирать единицы неслучайным образом, выборка становится нерепрезентативной. Например, если что-нибудь мешает нам отбирать их случайно. Представим себе, что мы хотим отобрать шары из нашего ящика случайным образом, но тут оказывается, что часть шаров кусается. Механизм, при котором мы будем брать только те шарики, которые даются нам в руки, - это механизм, нарушающий случайность и поэтому нарушающий репрезентативность. В этом случае, сколько бы мы шариков ни взяли из ящика (даже если мы возьмем все шарики, которые не кусаются), у нас будет нерепрезентативная выборка, потому что мы не учтем ни одного из тех, что кусаются, - они просто минуют нашу выборку.
Самая большая проблема с кусающимися шарами состоит в том, что они могут отличаться от тех, которые идут к нам в руки, и отличаться как раз по тому признаку, который нас интересует. Такая ситуация называется систематической ошибкой выборки.
Нужно отличать ситуацию неточной репрезентации, которую мы описали выше, от ситуации нерепрезентативности. Это разные проблемы, и у них разные способы решения. Нельзя решить одну из них путем решения другой. Если выборке не хватает репрезентативности, бесполезно ее увеличивать. Более того, большие выборки в социальных обследованиях имеют свойство накапливать ошибки, поэтому с помощью сильного увеличения выборки проблему репрезентации можно только усугубить.
Почему репрезентативность невозможна
В примечаниях к таблицам с результатами опросов часто можно увидеть, что «объем выборки составляет 1600 человек, выборка репрезентативна по полу и возрасту». Из сказанного выше очевидно, что это два разных параметра: указание на репрезентативность не связано с объемом выборки. На самом деле здесь имеется в виду то, что выполнялись определенные процедуры, для того чтобы обеспечить соответствие между выборкой и генеральной совокупностью. Например, чтобы обеспечить репрезентативность по полу, в выборку набирают мужчин и женщин в таких же соотношениях, какие существуют среди россиян по данным переписи. Но репрезентативность по полу не означает репрезентативности, например, по политическим взглядам.
Почему приходится выравнивать выборку по полу и другим социально-демографическим категориям? Потому что подлинную репрезентативность может обеспечить только случайная выборка, а реализовать ее на практике невозможно по массе причин. Как только вы попытаетесь это сделать, вы столкнетесь с множеством проблем - неважно, каким методом вы захотите воспользоваться. Часть респондентов вообще окажется недоступной для вашего метода (скажем, для личных интервью большой проблемой являются дома с домофонами и охраной), еще часть будет отсутствовать, не отвечать или предпочтет заниматься своими делами. Есть люди, у которых есть языковые проблемы, и они не могут с нами говорить. Есть люди, которые не понимают, зачем это нужно, и они не хотят с нами говорить. Все это - серьезные нарушения случайности, которые делают ее реализацию невозможной.
Те, кто сводит проблему репрезентации в массовых опросах к статистике, забывают о том, что люди - это очень специфические шарики. Есть шарики, которые убегают и прячутся. Есть шарики, которые кусаются. Они не пассивные объекты, они дают сдачи. Они говорят: «Я не хочу участвовать в твоем опросе», тем самым нарушают случайность. Поэтому в строгом смысле слова репрезентативность в массовых опросах, конечно, невозможна ни в каком виде.
Выработан механизм, с помощью которого обычно обеспечивается видимость репрезентативности: мы выравниваем выборку по некоторым категориям и делаем вид, что по всем остальным возможным категориям она тоже выровнена. На самом деле у нас нет никаких оснований это утверждать. Но проблема в том, что нет и никакой возможности это проверить - опять же в силу того, что некоторые шарики кусаются. Для того чтобы проверить наличие систематической ошибки, проверяющему пришлось бы сходить к тем, кого мы не опросили, и опросить их. Но они, как мы помним, совсем не хотят, чтобы их опрашивали. Опросить тех, кто категорически не отвечает, невозможно. Поэтому все работают на предположении, что, если мы выровняли выборку по двум-трем параметрам, она репрезентирует всю совокупность, хотя у этого предположения и нет никаких серьезных оснований.
Репрезентативная выборка - технология, заимствованная социологами из статистики. Поэтому она неизбежно несет в себе элементы математико-статистической картины мира. Пожалуй, самое сильное допущение состоит в том, что сам по себе выборочный опрос политически и социологически нейтрален: участие и неучастие в опросе не несет в себе политического смысла и не связано с другими социологически важными параметрами. Но сегодня опросы стали одним из главных политических институтов и превратились в ключевого посредника между крупными корпорациями и потребителями. В этих условиях верить в их политическую стерильность уже невозможно. Однако мы по-прежнему мало знаем о том, как опросы понимаются в современных обществах и что они в действительности репрезентируют.
Суммарная численность объектов наблюдения (люди, домохозяйства, предприятия, населенные пункты и т.д.), обладающих определенным набором признаков (пол, возраст, доход, численность, оборот и т.д.), ограниченная в пространстве и времени. Примеры генеральных совокупностей
- Все жители Москвы (10,6 млн. человек по данным переписи 2002 года)
- Мужчины-Москвичи (4,9 млн. человек по данным переписи 2002 года)
- Юридические лица России (2,2 млн. на начало 2005 года)
- Розничные торговые точки, осуществляющие продажу продуктов питания (20 тысяч на начало 2008 года) и т.д.
Выборка (Выборочная совокупность)
Часть объектов из генеральной совокупности, отобранных для изучения, с тем чтобы сделать заключение обо всей генеральной совокупности. Для того чтобы заключение, полученное путем изучения выборки, можно было распространить на всю генеральную совокупность, выборка должна обладать свойством репрезентативности.
Репрезентативность выборки
Свойство выборки корректно отражать генеральную совокупность. Одна и та же выборка может быть репрезентативной и
нерепрезентативной для разных генеральных совокупностей.
Пример:
- Выборка, целиком состоящая из москвичей, владеющих автомобилем, не репрезентирует все население Москвы.
- Выборка из российских предприятий численностью до 100 человек не репрезентирует все предприятия России.
- Выборка из москвичей, совершающих покупки на рынке, не репрезентирует покупательское поведение всех москвичей.
В то же время, указанные выборки (при соблюдении прочих условий) могут отлично репрезентировать
москвичей-автовладельцев, небольшие и средние российские предприятия и покупателей, совершающих покупки на рынках
соответственно.
Важно понимать, что репрезентативность выборки и ошибка выборки – разные явления. Репрезентативность, в отличие от
ошибки никак не зависит от размера выборки.
Пример:
Как бы мы не увеличивали количество опрошенных москвичей-автовладельцев, мы не сможем репрезентировать этой выборкой
всех москвичей.
Ошибка выборки (доверительный интервал)
Отклонение результатов, полученных с помощью выборочного наблюдения от истинных данных генеральной совокупности.
Ошибка выборки бывает двух видов – статистическая и систематическая. Статистическая ошибка зависит от размера
выборки. Чем больше размер выборки, тем она ниже.
Пример:
Для простой случайной выборки размером 400 единиц максимальная статистическая ошибка (с 95% доверительной
вероятностью) составляет 5%, для выборки в 600 единиц – 4%, для выборки в 1100 единиц – 3% Обычно, когда говорят об
ошибке выборки, подразумевают именно статистическую ошибку.
Систематическая ошибка зависит от различных факторов, оказывающих постоянное воздействие на исследование и смещающих
результаты исследования в определенную сторону.
Пример:
- Использование любых вероятностных выборок занижает долю людей с высоким доходом, ведущих активный образ жизни. Происходит это в силу того, что таких людей гораздо сложней застать в каком-либо определенном месте (например, дома).
- Проблема респондентов, отказывающихся отвечать на вопросы (доля «отказников» в Москве, для разных опросов, колеблется от 50% до 80%)
В некоторых случаях, когда известны истинные распределения, систематическую ошибку можно нивелировать введением квот или перевзвешиванием данных, но в большинстве реальных исследований даже оценить ее бывает достаточно проблематично.
Типы выборок
Выборки делятся на два типа:
- вероятностные
- невероятностные
1. Вероятностные выборки
1.1 Случайная выборка (простой случайный отбор)
Такая выборка предполагает однородность генеральной совокупности, одинаковую вероятность доступности всех элементов,
наличие полного списка всех элементов. При отборе элементов, как правило, используется таблица случайных чисел.
1.2 Механическая (систематическая) выборка
Разновидность случайной выборки, упорядоченная по какому-либо признаку (алфавитный порядок, номер телефона, дата
рождения и т.д.). Первый элемент отбирается случайно, затем, с шагом ‘n’ отбирается каждый ‘k’-ый элемент. Размер
генеральной совокупности, при этом – N=n*k
1.3 Стратифицированная (районированная)
Применяется в случае неоднородности генеральной совокупности. Генеральная совокупность разбивается на группы
(страты). В каждой страте отбор осуществляется случайным или механическим образом.
1.4 Серийная (гнездовая или кластерная) выборка
При серийной выборке единицами отбора выступают не сами объекты, а группы (кластеры или гнёзда). Группы отбираются
случайным образом. Объекты внутри групп обследуются сплошняком.
2.Невероятностные выборки
Отбор в такой выборке осуществляется не по принципам случайности, а по субъективным критериям – доступности,
типичности, равного представительства и т.д..
2.1. Квотная выборка
Изначально выделяется некоторое количество групп объектов (например, мужчины в возрасте 20-30 лет, 31-45 лет и 46-60
лет; лица с доходом до 30 тысяч рублей, с доходом от 30 до 60 тысяч рублей и с доходом свыше 60 тысяч рублей) Для
каждой группы задается количество объектов, которые должны быть обследованы. Количество объектов, которые должны
попасть в каждую из групп, задается, чаще всего, либо пропорционально заранее известной доле группы в генеральной
совокупности, либо одинаковым для каждой группы. Внутри групп объекты отбираются произвольно. Квотные выборки
используются в достаточно
часто.
2.2. Метод снежного кома
Выборка строится следующим образом. У каждого респондента, начиная с первого, просятся контакты его друзей, коллег,
знакомых, которые подходили бы под условия отбора и могли бы принять участие в исследовании. Таким образом, за
исключением первого шага, выборка формируется с участием самих объектов исследования. Метод часто применяется, когда
необходимо найти и опросить труднодоступные группы респондентов (например, респондентов, имеющих высокий доход,
респондентов, принадлежащих к одной профессиональной группе, респондентов, имеющих какие-либо схожие хобби/увлечения
и т.д.)
2.3 Стихийная выборка
Опрашиваются наиболее доступные респонденты. Типичные примеры стихийных выборок – в газетах/журналах, отданные респондентам на самозаполнение, большинство
интернет-опросов. Размер и состав стихийных выборок заранее не известен, и определяется только одним параметром –
активностью респондентов.
2.4 Выборка типичных случаев
Отбираются единицы генеральной совокупности, обладающие средним (типичным) значением признака. При этом возникает
проблема выбора признака и определения его типичного значения.
Курс лекций по теории статистики
Более подробную информацию по выборочным наблюдениям можно получить просмотрев .